
Entrenamiento de Modelos de IA
La Clave para la Innovación y la Ventaja Competitiva
En un mercado digital saturado de herramientas y plataformas de IA, la simple adopción de soluciones pre-empaquetadas ya no es suficiente. La verdadera ventaja competitiva y el diferenciador que su empresa necesita para adelantarse a la competencia radica en una capacidad crucial: saber cómo personalizar y entrenar un modelo de IA para sus objetivos específicos.
Puede entrenar un modelo de IA para realizar casi cualquier tarea que su negocio requiera, desde el reconocimiento de patrones complejos en grandes volúmenes de datos hasta la creación de contenido completamente nuevo y original. La clave para desbloquear este potencial ilimitado reside en contar con los recursos adecuados y comprender a fondo el proceso.
Siga leyendo para obtener una visión en profundidad del proceso de entrenamiento de un modelo de IA y descubra cómo transformar su estrategia empresarial.
¿Qué es el Entrenamiento de Modelos de IA?
El entrenamiento de modelos de IA es el proceso fundamental de construir una herramienta inteligente y personalizada capaz de analizar e interpretar vastas cantidades de datos. Su objetivo principal es que el modelo de IA pueda realizar tareas específicas con precisión y eficiencia, contribuyendo a un objetivo empresarial claro.
Estas tareas pueden incluir:
- Generación de contenido nuevo: Creación de textos, imágenes, audio o incluso código.
- Realización de predicciones: Estimación de tendencias futuras, demanda de productos o comportamientos del cliente.
- Clasificación de información: Categorización de documentos, detección de spam o identificación de objetos en imágenes.
Los datos son, sin duda, el recurso más importante en este proceso. Los datos que se introducen en un modelo (ya sea sin entrenar o pre entrenado) deben ser de alta calidad, relevantes y seleccionados cuidadosamente por profesionales. Solo así el modelo podrá detectar patrones, relaciones y matices cruciales para un aprendizaje efectivo.
Si bien existen diversos tipos de modelos de IA y técnicas de entrenamiento, en este artículo nos centraremos en dos de los enfoques más transformadores: la IA Generativa (GenAI) y el Aprendizaje Automático (Machine Learning – ML).
¿Qué es la IA Generativa (GenAI)?
Los modelos de IA Generativa (GenAI) utilizan datos e indicaciones generadas por humanos (o por otras IA) para crear contenido nuevo y original. Su capacidad para producir texto, imágenes, audio, video y código, que no existía previamente, la convierte en una tecnología revolucionaria.
Por ejemplo, un modelo GenAI puede empoderar a ingenieros y diseñadores, permitiéndoles acelerar el proceso de diseño mediante la generación de múltiples ideas y prototipos a partir de simples indicaciones.
¿Qué es el Aprendizaje Automático (Machine Learning – ML)?
Los modelos de Aprendizaje Automático (ML) utilizan datos para tomar decisiones o realizar predicciones sin haber sido explícitamente programados para cada escenario. Su poder reside en la capacidad de aprender de patrones y tendencias en los datos históricos.
Un ejemplo práctico es un modelo de ML que analiza datos de clientes anteriores, como historiales de compra y navegación, para predecir y recomendar otros productos que un cliente específico podría disfrutar, optimizando así las ventas cruzadas y la experiencia del usuario.
Comienza con Modelos Preentrenados Existentes
Antes de embarcarte en el entrenamiento de un modelo de IA desde cero, es prudente investigar si ya existe un modelo pre entrenado que se ajuste, total o parcialmente, a tu caso de uso. Estos modelos, ya «educados» con vastas cantidades de datos, pueden ser aplicados directamente o ajustados («fine-tuned») a tus necesidades específicas, ahorrando tiempo y recursos significativos.
Ejemplos de modelos pre entrenados populares:
- BERT (Google): Excelente para la comprensión de textos, respuesta a preguntas y análisis de sentimientos.
- GPT (OpenAI): Un referente en la generación de texto, desarrollo de chatbots y resumen automático de contenido.
- T5 (Google): Versátil para traducción, resumen y clasificación de textos.
- DeepSpeech (Mozilla):** Especializado en reconocimiento automático de voz (ASR).
- CLIP (OpenAI): Capaz de comprender la relación entre imágenes y texto.
Puedes encontrar una amplia selección de modelos preentrenados en repositorios y plataformas como:
Hugging Face: Un centro comunitario para modelos de Machine Learning.
TensorFlow Hub: Repositorio de modelos reutilizables de TensorFlow.
PyTorch Hub: Modelos pre entrenados y código de PyTorch.
Zoológicos de modelos de grandes empresas como Meta, Google, OpenAI, ONNX, entre otros.
¿Es Difícil Entrenar un Modelo de IA?
La respuesta es que el entrenamiento de un modelo de IA es, a menudo, más fácil de decir que de hacer. La dificultad real depende en gran medida del nivel de experiencia de su equipo y de la complejidad del propósito del modelo. En muchos casos, podría necesitar asistencia especializada.
Tradicionalmente, tareas de IA como el entrenamiento de modelos se han confiado a científicos de datos o profesionales de TI altamente cualificados. Estos expertos poseen la formación y las habilidades técnicas necesarias para:
- Recopilar y gestionar la calidad de los datos de manera efectiva.
- Mantener la privacidad y seguridad de los datos conforme a las regulaciones.
- Seguir los requisitos de infraestructura computacional para el entrenamiento.
- Comprender a fondo las funciones y limitaciones del modelo.
Dicho esto, entrenar un modelo de IA sin experiencia previa no es imposible. Requiere paciencia, dedicación y el uso de recursos adecuados. Las herramientas de entrenamiento de IA sin código (no-code) o de bajo código (low-code), como Amazon SageMaker, Microsoft AI Builder, Google AutoML y otras plataformas similares, están democratizando este campo, permitiendo a usuarios no técnicos involucrarse en la creación y personalización de modelos de IA.
—
7 Pasos Clave en el Proceso de Entrenamiento de un Modelo de IA
El entrenamiento de un modelo de IA es un viaje estructurado en etapas que, si se siguen correctamente, conducen a resultados exitosos.
1. Identificar el Problema
Comprender con absoluta claridad el problema que necesita resolver es el primer y más crítico paso. Esta definición inicial le ayudará a determinar los datos relevantes que necesitará recopilar y el tipo de modelo de IA más adecuado.
Algunos ejemplos de casos de uso y su relación con la identificación del problema:
¿Necesita una forma más sencilla de identificar el fraude? El modelo de IA requerirá datos que incluyan numerosos ejemplos de actividades fraudulentas pasadas.
¿Busca mejorar la experiencia del cliente? Su modelo de IA necesitará ser entrenado con datos sobre los hábitos, demografía y preferencias de sus clientes.
¿Necesita una forma más rápida de generar contenido nuevo? Podrá usar técnicas de ingeniería de prompts para enseñar al modelo de IA cómo generar los resultados correctos y deseados.
2. Recopilar, Organizar y Preparar sus Datos
Imagine que mañana tiene un examen de historia, pero la noche anterior solo estudió el proceso de la fotosíntesis. Es muy probable que el resultado no sea el deseado. Considere el entrenamiento de un modelo de IA como un escenario similar: la calidad de un modelo depende directamente de la calidad de los datos que le proporcione. Y en el mundo de la IA, a menudo, la calidad de los datos supera con creces a la cantidad.
Los datos de entrenamiento deben ser diversos, representativos y, crucialmente, estar libres de sesgos. El uso de datos específicos de su empresa es vital, ya que ayuda al modelo a comprender las complejidades y particularidades de su negocio, lo que se traduce en resultados mucho más precisos y relevantes.
Dependiendo de sus recursos y el caso de uso, puede proporcionar a un modelo de IA con datos reales o datos sintéticos:
Datos reales: Se recopilan a partir de actividades auténticas, como interacciones en redes sociales, comentarios de clientes (encuestas, sondeos, reseñas, etc.) o registros transaccionales.
Datos sintéticos: Se generan artificialmente para simular situaciones específicas. En el sector de la salud, por ejemplo, se utilizan ampliamente para entrenar modelos de IA mientras se mantiene la privacidad de la información sensible del paciente.
5 Tipos de Datos de Entrenamiento de Modelos de IA:
Según su caso de uso, necesitará diferentes tipos de datos para el entrenamiento:
- Datos textuales: Incluyen información de páginas web, libros, artículos académicos, documentos gubernamentales y otras fuentes. Son esenciales para enseñar a los modelos de IA a procesar y generar lenguaje humano.
- Datos de audio: Se centran en música, sonidos de animales, sonidos ambientales y, por supuesto, el habla humana. Permiten a los modelos aprender a detectar, comprender y procesar acentos, patrones de habla y emociones.
- Datos de imagen: Incluyen imágenes digitales utilizadas para tareas como reconocimiento facial, imágenes médicas digitales (radiografías, resonancias) y detección de objetos.
- Datos de video: Se aplican a diversos formatos de video y pueden utilizarse para entrenar aplicaciones como sistemas de reconocimiento facial en tiempo real o sistemas de vigilancia inteligentes.
- Datos de sensores: Incluyen lecturas de temperatura, datos biométricos, aceleración de un objeto, etc. Son cruciales para entrenar modelos de IA para vehículos autónomos, automatización industrial, dispositivos IoT (Internet de las Cosas) y ciudades inteligentes.
Los datos que utilice deben ser organizados y preparados meticulosamente mediante el procesamiento de datos. Esta tarea, a menudo realizada por científicos de datos, implica eliminar inconsistencias, valores atípicos y ruidos para aumentar la calidad y la relevancia de su conjunto de datos, asegurando un aprendizaje óptimo del modelo.
3. Elegir el Tipo Adecuado de Modelo de IA
Retomando el primer paso, donde identificó el problema a resolver, es momento de determinar si un modelo de IA Generativa (GenAI) o de Aprendizaje Automático (ML) le ayudará a alcanzar su objetivo.
A continuación, una tabla rápida con las diferencias clave:
IA generativa | Aprendizaje automático | |
| ¿Qué hace? | Genera contenido nuevo y original en tiempo real basado en datos de entrenamiento. | Hace predicciones o toma decisiones sin programación explícita. |
| ¿Cómo funciona? | Utiliza redes neuronales y aprendizaje profundo para encontrar patrones en datos existentes para crear contenido nuevo. | Aprende analizando e interpretando datos existentes para encontrar patrones y tendencias. |
| Ejemplos de salida | Texto original, imágenes, audio, vídeo, código y otros resultados. | Recomendaciones, detección de anomalías y clasificación basada en una puntuación de confianza. |
4. Elegir una Técnica de Entrenamiento
Ahora, necesita determinar la técnica específica para entrenar su modelo de IA. Al investigar las opciones, sea práctico y considere los siguientes factores:
- Recursos disponibles: ¿Qué capacidad computacional y de almacenamiento tiene?
- Costos: ¿Cuál es el presupuesto para el entrenamiento y el mantenimiento?
- Requisitos computacionales: ¿Necesita GPUs de alto rendimiento o puede usar CPUs?
- Complejidad: ¿Qué tan intrincado es el problema que intenta resolver?
- Plazos: ¿Cuándo necesita tener el modelo listo y en producción?
Existen muchísimas opciones de entrenamiento tanto para la IA Generativa como para el Aprendizaje Automático. Cada proceso de entrenamiento es único, pero nos centraremos en algunas de las técnicas más utilizadas y potentes.
Técnicas de Entrenamiento de IA Generativa
Transformadores:
Un transformador es una arquitectura de red neuronal que se ha vuelto fundamental en el procesamiento del lenguaje natural (NLP). Su capacidad para convertir un tipo de entrada en un tipo de salida diferente es revolucionaria. Los transformadores aprenden el contexto y el significado de los datos, rastreando las relaciones complejas entre los componentes de una secuencia.
Probablemente haya visto la «T» en GPT (Transformador Generativo Preentrenado) de ChatGPT. Casi todos los Grandes Modelos de Lenguaje (LLM) actuales funcionan con transformadores debido a su excepcional capacidad para traducir texto y voz en tiempo real con una precisión asombrosa. Un ejemplo popular de esto es el Traductor de Google, que permite traducir una oración de un idioma a otro casi instantáneamente.
Redes Generativas Antagónicas (GANs):
- Las Redes Generativas Antagónicas (GANs) consisten en dos redes neuronales que compiten entre sí, una dinámica que impulsa un aprendizaje excepcionalmente robusto:
- El Generador: Crea datos de muestra artificiales (por ejemplo, imágenes falsas) con el objetivo de engañar al Discriminador, haciéndole creer que son reales.
- El Discriminador: Aprende a distinguir qué muestras provienen del Generador (falsas) y cuáles son datos reales del dominio.
Los datos reales se envían al Discriminador para que pueda refinar su capacidad de distinguir entre lo auténtico y lo sintético. La función del Generador es engañar al Discriminador. Si el Generador tiene éxito, el Discriminador necesita más entrenamiento para detectar mejor las «falsificaciones». Si el Discriminador tiene éxito, el Generador debe ajustar su modelo para crear falsificaciones más convincentes. Este juego constante de «gato y ratón» perfecciona ambos modelos.
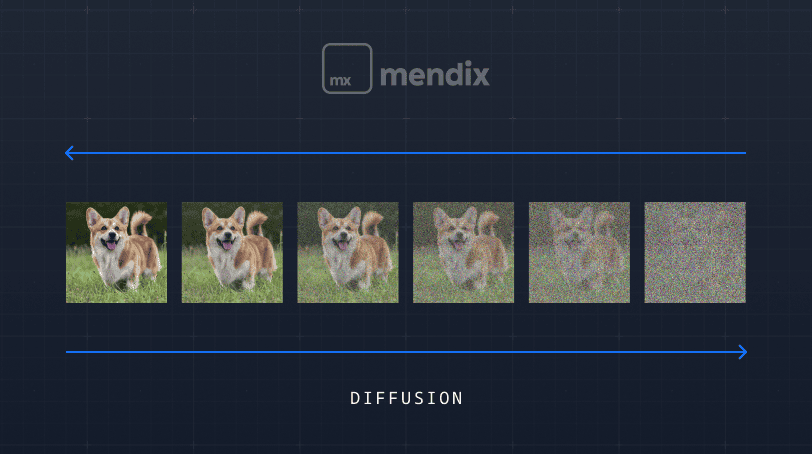
Modelos de Difusión:
Los modelos de difusión son principalmente utilizados para generar imágenes realistas y de alta calidad. Así funciona el proceso:
1. El proceso comienza alimentando el modelo con datos de entrenamiento, que en este caso son imágenes.
2. A continuación, se agrega ruido aleatorio (ruido gaussiano) a los datos existentes, difuminando progresivamente la imagen original.
3. Luego, el modelo invierte este proceso, aprendiendo a transformar el ruido de vuelta en una salida estructurada y coherente, recreando la imagen original o generando una nueva similar.
Un buen ejemplo para entender la difusión es el de un artista entrenado en la restauración de pinturas. Una pintura muy manchada puede ser irreconocible, pero a medida que el artista trabaja en su restauración, aprende los detalles más minuciosos de la obra original. Al terminar, no solo puede restaurarla, sino incluso recrear la pintura desde cero con gran fidelidad.
Técnicas de Entrenamiento de Aprendizaje Automático
Aprendizaje Supervisado:
El aprendizaje supervisado implica entrenar un algoritmo con conjuntos de datos etiquetados y seleccionados por humanos. La parte «supervisada» de este proceso son precisamente estos datos etiquetados, organizados por categoría o resultado deseado. Esto proporciona al algoritmo una comprensión fundamental de los resultados esperados, permitiéndole aprender a mapear entradas a salidas correctas.
La clasificación de imágenes es un ejemplo clásico. Supongamos que ha etiquetado conjuntos de datos con diferentes tipos de plantas, incluyendo su tamaño, color, forma de las hojas, etc. Con el aprendizaje supervisado, puede crear una aplicación que ayude a los usuarios a identificar el tipo de planta que tienen frente a ellos con solo tomar una foto.
Aprendizaje No Supervisado:
A diferencia del supervisado, el aprendizaje no supervisado no requiere conjuntos de datos etiquetados ni intervención humana directa durante el entrenamiento.
En cambio, esta técnica se encarga de encontrar patrones y relaciones por sí misma dentro de los datos, sin una comprensión predefinida de su significado. Un ejemplo común es la venta cruzada en sitios web de comercio electrónico. La sección de productos recomendados se rellena automáticamente mediante un modelo de aprendizaje no supervisado que analiza los datos de los clientes, encuentra patrones en sus comportamientos de compra y sugiere complementos o artículos similares que podrían interesarles.
Aprendizaje Semi supervisado:
El aprendizaje semi supervisado es una combinación inteligente de aprendizaje supervisado y no supervisado. Esta técnica utiliza tanto datos etiquetados como no etiquetados para entrenar modelos, aprovechando lo mejor de ambos mundos.
En este proceso, el modelo recibe una pequeña cantidad de datos etiquetados y una gran cantidad de datos sin etiquetar. El modelo utiliza los datos etiquetados para comprender las características básicas y luego aplica este conocimiento para realizar ajustes y comprender los datos sin etiquetar. Esto es especialmente útil, ya que etiquetar y organizar grandes volúmenes de datos es un proceso costoso y que requiere mucho tiempo. El aprendizaje semi supervisado es un equilibrio ideal entre los altos costos del aprendizaje supervisado y la complejidad del aprendizaje no supervisado.
5. Entrenar el Modelo
El entrenamiento de modelos de IA es un proceso iterativo y continuo. Si bien el proceso exacto de entrenamiento y validación depende del modelo específico y la técnica elegida, la premisa general es la misma: se introducen los datos preparados en el modelo para que aprenda a comprender patrones y relaciones subyacentes.
En esta fase de entrenamiento, es crucial identificar errores e implementar cambios de manera proactiva para aumentar la precisión de los resultados. La retroalimentación constante ayuda al sistema a perfeccionarse, ajustando sus parámetros para minimizar errores y mejorar su rendimiento general.
Es importante tener cuidado con el sobreajuste (overfitting), un problema común durante el entrenamiento de modelos de IA. Esto ocurre cuando el modelo se sesga excesivamente hacia el conjunto de datos de entrenamiento o empieza a memorizarlo en lugar de aprender a generalizar a partir de él. Un modelo sobreajustado rendirá pobremente con datos nuevos o no vistos.
6. Probar y Validar el Modelo
La IA, especialmente en sus etapas iniciales de aprendizaje, no es perfecta y es probable que cometa errores. Por ello, probar la precisión de un modelo de IA es un paso indispensable. Esto se logra alimentándolo con datos independientes que no formaron parte del proceso de entrenamiento inicial.
Si el modelo no funciona como se esperaba o su precisión es insuficiente, es necesario:
- Ajustar el modelo: Modificar sus parámetros o arquitectura.
- Recopilar más datos: Aumentar la cantidad o diversidad de datos de entrenamiento.
- Repetir el proceso de entrenamiento: Iterar sobre los pasos anteriores con los ajustes realizados.
- Volver a probar: Validar las mejoras obtenidas.
7. Implementar el Modelo
Una vez que su modelo de IA ha demostrado ser preciso y cumple con las expectativas de rendimiento, puede proceder a su implementación. Esto puede hacerse a través de diversas vías: mediante APIs (Interfaces de Programación de Aplicaciones) para integrarlo en otras aplicaciones, desplegándolo en entornos de nube (como AWS, Azure, Google Cloud) o directamente en una aplicación existente.
El Entrenamiento Continúa: La IA es un Activo Vivo
Una vez que su modelo de IA está entrenado e implementado, el trabajo no termina. La IA es conocida por sus «alucinaciones» y errores, especialmente en entornos dinámicos, por lo que deberá supervisar continuamente su rendimiento y su capacidad para operar en escenarios del mundo real.
Además, a medida que sus datos aumenten y evolucionen, será necesario volver a entrenar el modelo periódicamente para mantener su relevancia y precisión. Los datos son el reflejo del mundo real, y el mundo real cambia constantemente.
Pero después de todo el trabajo duro, la experimentación y el entrenamiento iterativo, tendrá un modelo de IA totalmente personalizado que entiende su negocio mejor que cualquier solución genérica, convirtiéndose en un activo estratégico inestimable.
¿Su empresa ya está explorando el potencial de la IA personalizada? ¡Escribanos para compartirnos los desafíos que le gustaría resolver con un modelo de IA a medida! Solicite una demo de Mendix
You may also like

Las Migraciones Tecnológicas: Clave para la Competitividad y Sostenibilidad Empresarial
Las migraciones tecnológicas son fundamentales para que las empresas se mantengan competitivas y so

¿Cómo puedo extender el front-end de Mendix?
Mendix hace posible crear extensiones que se integran a la perfección con Mendix Studio y Mendix St

Crecimiento exponencial con Pioneer at the Pinnacle: Nate Walton
Durante más de dos años y medio, el equipo de la Oficina de TI de la Universidad Brigham Young (BY
Post a comment