
Mendix, AWS y el Internet de las cosas
Mendix y AWS han estado trabajando juntos para crear una variedad de modelos y plantillas. Queríamos mostrar cómo estas grandes plataformas pueden trabajar juntas, como nuestros aceleradores de servicios financieros y seguros. Una de las cosas que queremos demostrarle es la integración entre Mendix y AWS. Este artículo describe la demostración que hemos construido y cómo lo hicimos.
Esta publicación está escrita en conjunto con Simon Black (gerente sénior de evangelismo y capacitación técnica), Alistair Crawford (evangelista de soluciones) y Adrian Preston (evangelista de soluciones).
El escenario
El escenario de la logística de la cadena de frío y cómo rastrear el transporte de mercancías con temperatura controlada. Para lograr esto, usamos Mendix para crear una interfaz de aplicación web compatible con los servicios de AWS. Usando estas herramientas, queríamos construir:
- Una aplicación web para usuarios de oficina
- Una versión móvil para el personal de campo
- La arquitectura de nube de AWS compatible para procesar y proporcionar los datos

Creación de la demostración, parte 1: IoT y AWS
Para simplificar la demostración de datos de la vida real (y eliminar la necesidad de un camión físico con sensores), decidimos crear un simulador de datos que luego usaríamos para alimentar los datos en los servicios de AWS.
Para manejar los datos de IoT en AWS, elegimos usar AWS Timestream, así que ahí es donde comenzamos. Creamos una fuente de datos de Timestream que representaba los datos del sensor para la temperatura y la humedad. También necesitaríamos los datos del viaje y los datos de los dispositivos finales de IoT; las cerraduras y el compresor de respaldo.
Los bloqueos son un valor booleano simple para almacenar, ya sea que estén activados o no. El compresor de respaldo también es un valor booleano de encendido o apagado, pero se retroalimentaría al simulador para los datos de Timestream, por lo que los datos de temperatura tenderían a bajar cuando se encendiera el compresor.
Una característica adicional de AWS que decidimos implementar fue el reconocimiento de imágenes. En el escenario que nos dieron, los camiones transportarían productos frescos, en este caso fruta, y debían inspeccionarse en el momento de la entrega. Una vez que se completó la entrega y la persona que inspeccionó los productos en el otro extremo tomó una fotografía, pudimos pasarla por AWS Rekognition y detectar si el producto es bueno o malo.
Aquí hay una breve descripción general de cómo se creó cada uno de estos conjuntos de datos y funciones en AWS.
Configuración de AWS IoT
Para recibir datos de los dispositivos, aprovechamos AWS IoT Core. Primero necesitamos configurar nuestros dispositivos, también conocidos en IoT como «Things» . Configuramos una «Thing» para los datos de nuestro vehículo desde el camión y otra «Thing» para cada contenedor en el camión. Esto nos ayudará a rastrear el vehículo y monitorear el estado de los contenedores.
Una vez que se configuran con las políticas de seguridad correctas, automáticamente tenemos acceso a los mecanismos de publicación y suscripción de MQTT utilizados para enviar y recibir datos.
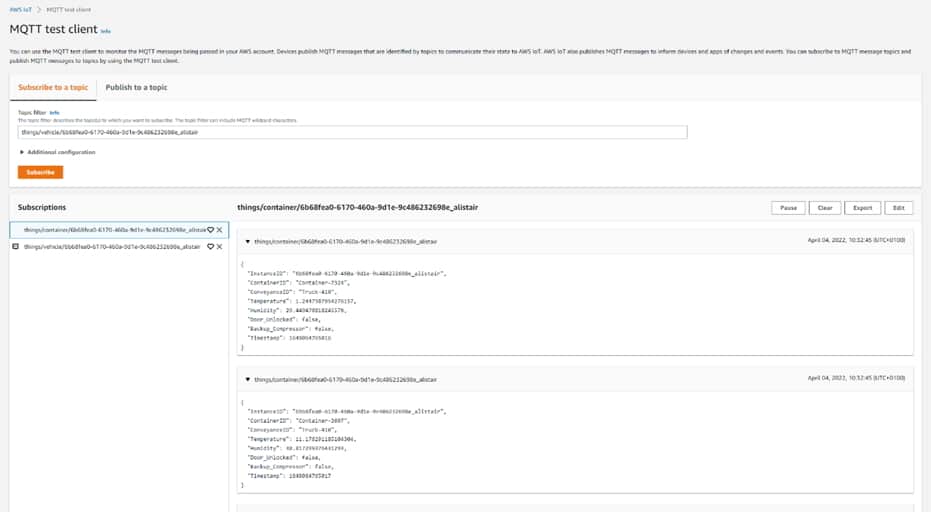
Por último, podemos configurar una regla en AWS IoT Core que almacenará los datos entrantes de nuestros vehículos y contenedores dentro de un TimestreamDB para su uso posterior.
Configuración de la base de datos de Amazon Timestream
La base de datos de Amazon Timestream es fácil de configurar. Creamos una base de datos llamada «logistics» y dentro de ella una tabla llamada «container» para contener los datos del sensor del contenedor y una tabla llamada «conveyance» para recibir los datos del camión.
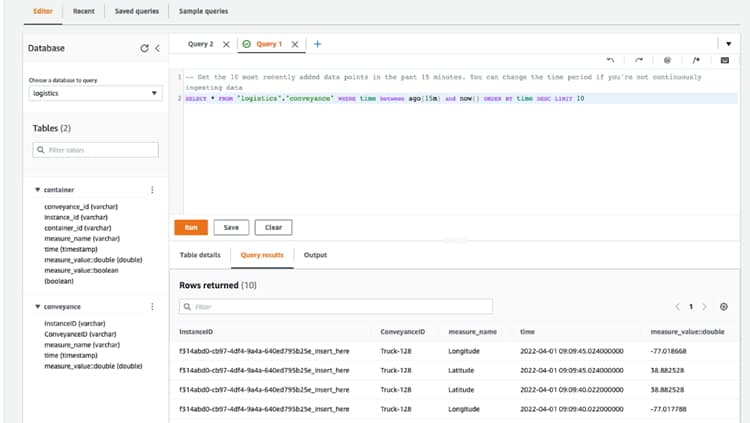
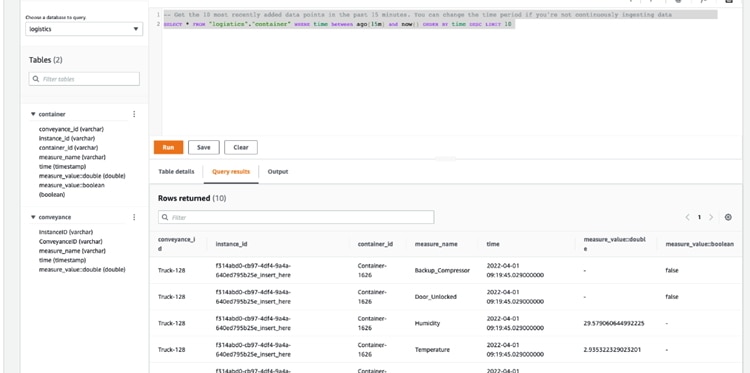
Para que haya algunos datos históricos disponibles en la base de datos de Amazon Timestream poco después de que se inicie la aplicación, la aplicación inicializa «things» agregando un conjunto de registros generados aleatoriamente a la base de datos. Esto se hace mediante una acción java que interactúa con el SDK de Java de AWS para acceder a la función de escritura de registros de Timestream.
Posteriormente, las reglas en AWS IoT Core agregan nuevos datos a las tablas de la base de datos. Las reglas toman los mensajes seleccionados que ha publicado el sensor/simulador a través de AWS IoT Core y los escribe en la tabla de base de datos especificada.
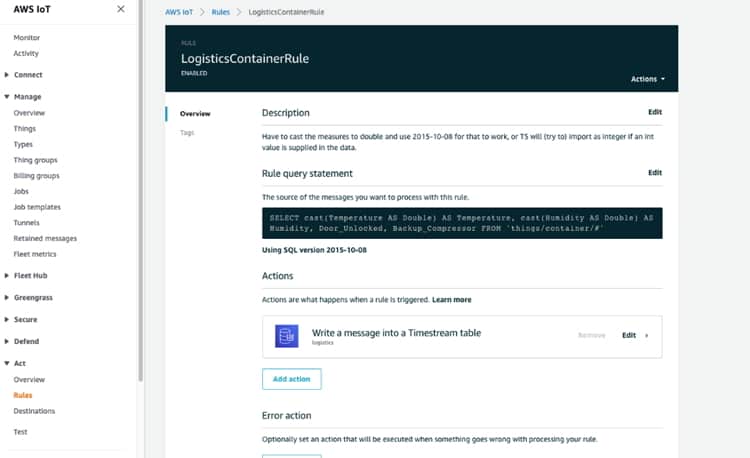
Una vez que tuvimos la base de datos de AWS Timestream en funcionamiento, necesitábamos crear algunos datos de viaje.
Generación de datos de viaje
En un escenario real con seguimiento de viaje y dispositivo, nuestro dispositivo de camión normalmente tendría un módulo GPS para enviar datos de ubicación, rumbo y velocidad. Esto nos daría los datos de latitud, longitud, MPH (o KPH) y aceleración.
Para nuestra simulación del viaje, hicimos uso de algunas rutas de simulación existentes que están disponibles para el público gracias a AWS. Tienen un gran conjunto de rutas estáticas que tienen origen, destino y luego una serie de etapas o puntos que se encuentran entre ellos en un patrón realista. Todo esto está en formato JSON y es fácilmente digerible.
Para la mayoría de los demás datos de los sensores, utilizamos algunas matemáticas simples para generar valores aleatorios que caen dentro de nuestros umbrales, por ejemplo, la temperatura y la humedad.
Habiendo generado los datos del viaje para poder simular el seguimiento del camión, necesitábamos implementar las funciones de reconocimiento de imágenes y construir el conjunto de datos.
Reconocimiento AWS
Para simplificar el proceso de inspección de la calidad de los productos (en nuestro caso, fruta), decidimos implementar alguna IA. AWS tiene una variedad de soluciones de inteligencia artificial y aprendizaje automático diseñadas para varios tipos de escenarios. Para el reconocimiento de imágenes y videos, AWS proporciona AWS Rekognition. Rekognition proporciona una variedad de modelos de aprendizaje automático preentrenados, además de permitirle entrenar los suyos propios. Para nuestro caso de uso, queríamos permitirle al usuario tomar una foto de alguna fruta e inspeccionar su calidad.
Primero, necesitábamos entrenar nuestro modelo de reconocimiento para comprender cómo se ven las frutas buenas y malas. Para construir un modelo efectivo, es importante que tenga un buen conjunto de datos. Cuantas más imágenes podamos proporcionar para entrenar el modelo, mejores resultados obtendremos. Afortunadamente para nosotros, había muchos conjuntos de datos abiertos gratuitos para ayudar a acelerar nuestro desarrollo. Encontramos este conjunto de datos que tenía miles de imágenes que representaban fruta podrida y fresca:
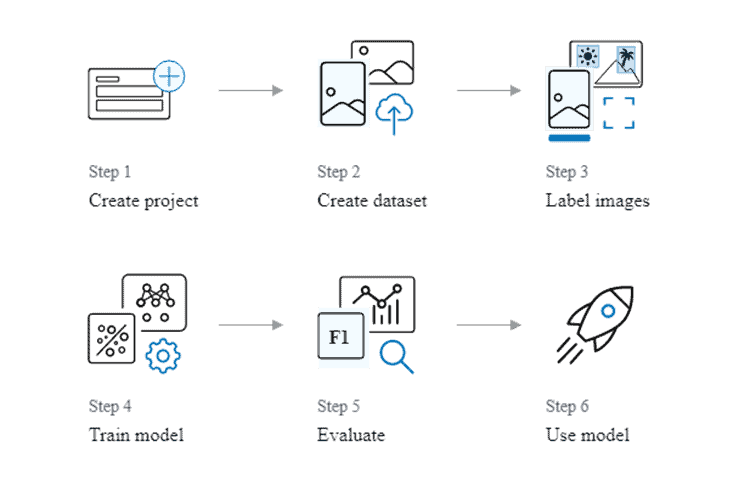
Tomamos este conjunto de datos y lo subimos a AWS S3 para que AWS Rekognition pudiera usar estas imágenes para entrenarse y probarse a sí mismo. Crear un modelo para detectar etiquetas personalizadas es rápido y fácil de hacer. En 6 pasos puedes construir un modelo detectando etiquetas:
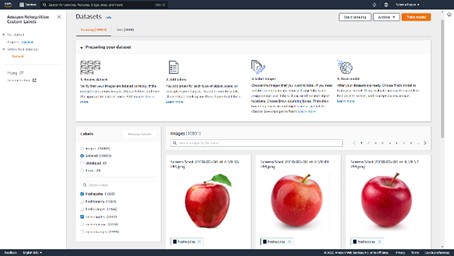
Al entrenar el conjunto de datos , AWS Rekognition puede etiquetar automáticamente sus imágenes en función de los nombres de carpeta utilizados en S3 o puede agregar etiquetas manualmente. Debido al gran conjunto de datos, decidimos utilizar la asignación automática de etiquetas. Esto significa que al construir el conjunto de datos, no tuvimos que agregar manualmente etiquetas a cada imagen . Esto nos ahorró mucho tiempo y esfuerzo. Al crear un conjunto de datos, es importante proporcionar un conjunto de datos de entrenamiento y un conjunto de datos de prueba. Esto permite que AWS Rekognition se entrene a sí mismo y luego pruebe qué tan preciso es el modelo que se creó usando el conjunto de entrenamiento.
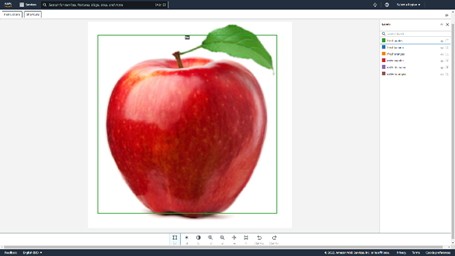
Una vez que el modelo se ha entrenado con los conjuntos de datos, lo que puede demorar alrededor de 30 minutos, se debe iniciar el modelo. Una vez entrenado y el modelo iniciado, está listo para aceptar solicitudes a través de la API de AWS, cuyos detalles se pueden encontrar más adelante en esta publicación, y detectar etiquetas en función de una entrada de imagen.
Construyendo la demo parte 2: Mendix
Para comenzar la compilación, trazamos algunos esquemas y flujos de procesos, y nuestro diseñador de UX ideó un diseño de Figma para guiar la apariencia de la aplicación.
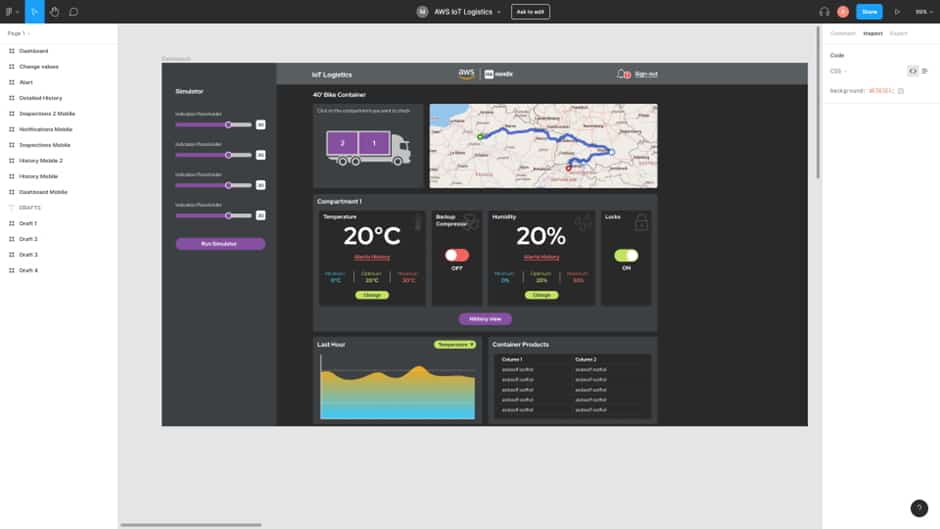
Ahora que sabíamos más o menos cómo se vería eventualmente, podíamos comenzar a juntar las distintas piezas.
- integraciones
- modelos de dominio
- Aplicaciones
La compilación comenzó con las herramientas de administración para respaldar el sistema y una forma de llenar previamente el sistema con datos. Creamos las entidades del modelo de dominio para almacenar la información que necesitábamos para los camiones, sus contenedores, los conductores y las mercancías que se transportarían. Luego, creamos rutinas para completar esto con datos de muestra para la demostración y para facilitar que otras personas lo usen en el futuro.
Luego, los camiones se vincularon a los datos del viaje y los contenedores se conectaron a la fuente de datos Timestream.
| Integración de Mendix con AWS Timestream | |
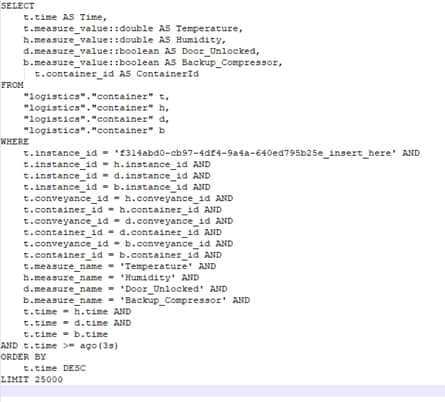 | Cuando la aplicación Logística necesita recuperar los datos históricos de IoT de Timestream, esto se hace configurando una instrucción SELECT y ejecutándola a través de la acción Java de consulta de Timestream. Esta es una acción de Java que se creó para usar el SDK de Java de AWS para ejecutar consultas en la base de datos de Timestream y devolver los resultados. |
Para respaldar la generación de datos y verificar que todo funcionaba, creamos algunas páginas de administración para obtener una vista previa, modificar y exportar los datos. La exportación es particularmente útil ya que los archivos JSON que creamos podrían usarse como fuente de datos para el llenado previo dentro de la aplicación de demostración.
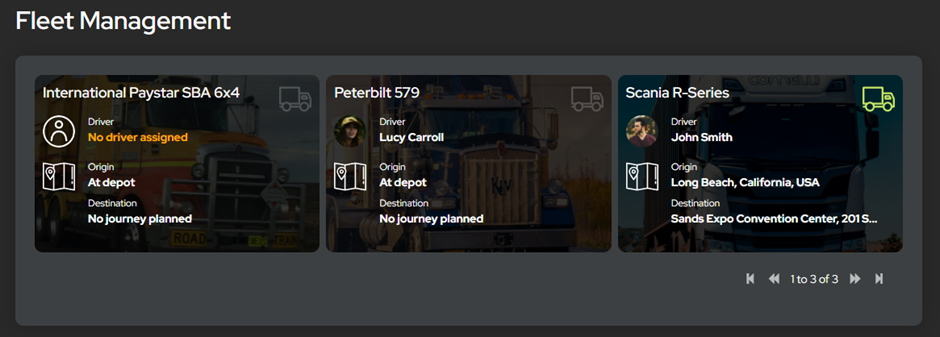
A continuación, presentamos en una página de descripción general la información del camión y del conductor que habíamos creado. Esto le da al usuario de la oficina administrativa la oportunidad de elegir qué vehículo quiere ver. Solo se puso en marcha un vehículo para la demostración, pero si hubiera habido varios, habría sido fácil elegir.
Hacer clic en un camión le brinda una vista de los detalles y el estado actual de ese camión. Aquí es donde entra la información simulada. Trabajando de arriba hacia abajo comenzamos con el selector de contenedores, ya que cada camión en nuestro sistema tiene dos contenedores, y esto controla la vista de los monitores en la sección a continuación.
El mapa en la parte superior derecha vino después. El widget predeterminado de Mendix es perfecto para mostrar ubicaciones, pero en ese momento no tenía una opción integrada para dibujar la línea de la ruta o mostrar fácilmente el camión en movimiento. Una exploración rápida en el mercado tampoco arrojó nada que hiciera lo que queríamos, por lo que creamos nuestro propio widget conectable usando React y JavaScript. Este nuevo widget muestra la línea de ruta, el camión moviéndose a lo largo de la línea y la dirección en la que se dirige.
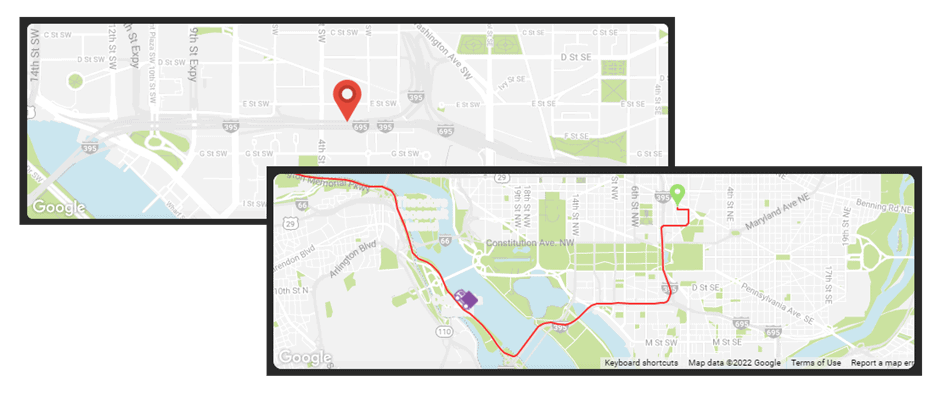
La sección inferior muestra actualizaciones de la temperatura y la humedad dentro del contenedor seleccionado y los productos que están transportando. Además, los conmutadores para el compresor de respaldo y las cerraduras. Todo esto necesitaba conectarse a nuestros datos de Timestream.
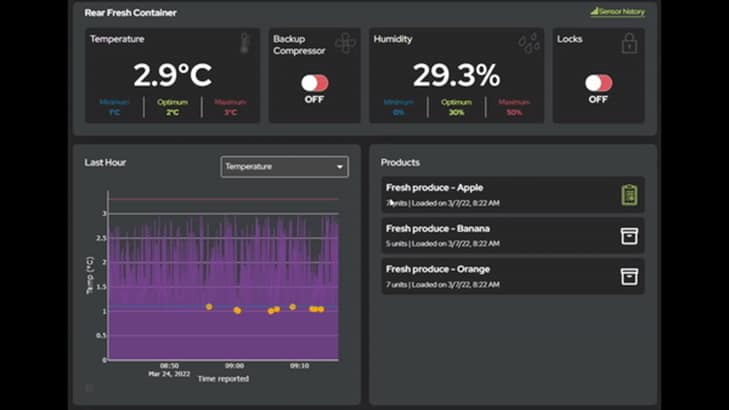
Luego, los datos se actualizan periódicamente para proporcionar información actualizada. Cualquier alerta desencadenada por el umbral de incumplimiento de la temperatura o la humedad se pasa al cliente a través de un socket web para una actualización casi instantánea. Ampliamos esta función con Amazon SNS para ofrecer también notificaciones por SMS y correo electrónico.
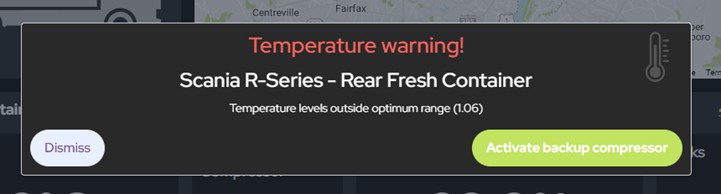
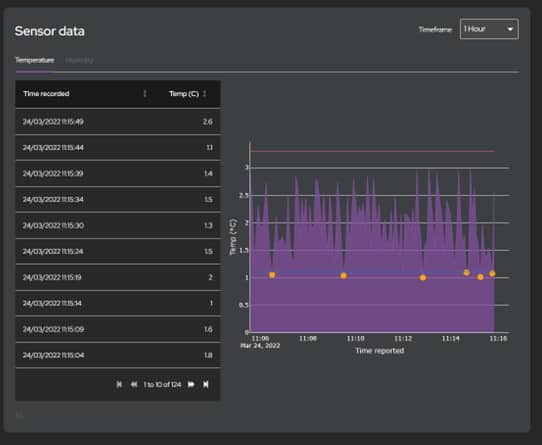
Todas las acciones se registran y presentan en una línea de tiempo que muestra los eventos clave en el viaje del camión, desde alertas hasta cuando las puertas están bloqueadas y desbloqueadas. Todos los datos del sensor también se presentan en una vista detallada.
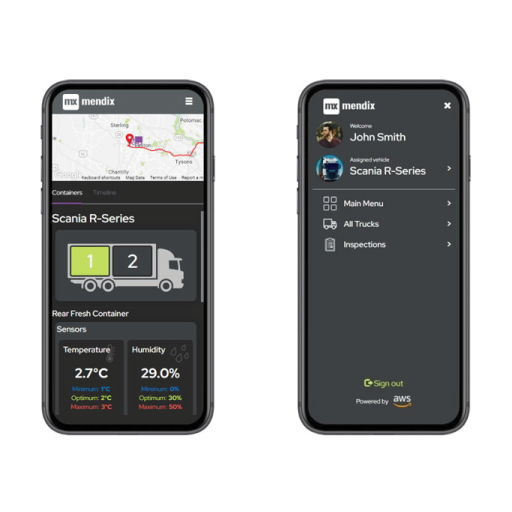
La pieza final del rompecabezas es la aplicación móvil para usuarios de campo. Para esta demostración, decidimos utilizar una aplicación web receptiva, en lugar de un dispositivo móvil nativo, por lo que gran parte del diseño se podía reutilizar entre el sistema administrativo y la versión móvil.
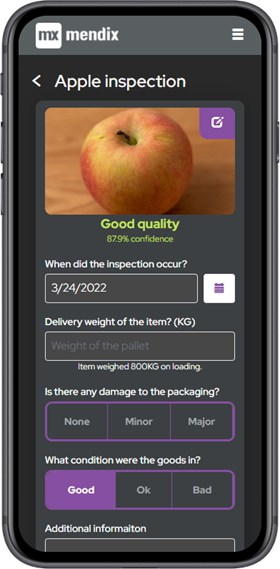
Lo último que se implementó fue el formulario de inspección y la API de Rekognition. El formulario es bastante simple; una imagen de la mercancía, la fecha de llegada y alguna valoración de su estado. Una vez que se toma la foto, se envía a la API de Rekognition, que entrenamos para reconocer manzanas buenas y malas en función de una gran muestra de imágenes. Devuelve una evaluación de calidad de buena o mala y la confianza que tiene en el resultado.
Integración de Mendix con AWS Rekognition
Es fácil integrar Mendix con AWS Rekognition. AWS a menudo ofrece varias formas de integración en su plataforma. Puede utilizar el SDK en el idioma que prefiera o elegir utilizar la API subyacente. Con Mendix teníamos dos opciones: usar el SDK de Java de AWS o integrarlo a las API usando las acciones de Mendix REST Microflow. Elegimos seguir la ruta REST, para minimizar nuestras dependencias de Java y usar la mayor cantidad posible de Mendix nativo (Mendix es, con mucho, la ruta más simple y rápida, ya que la integración con una API REST es un proceso sencillo en lugar de la integración con un SDK con que no conocemos).
Primero nos enfocamos en implementar la actividad principal, que era detectar las etiquetas personalizadas. Usando esta API, pudimos construir el mapeo en Mendix: https://docs.aws.amazon.com/rekognition/latest/APIReference/API_DetectCustomLabels.html
Primero, construimos un fragmento JSON para la respuesta y un mapeo de importación para procesar la respuesta.
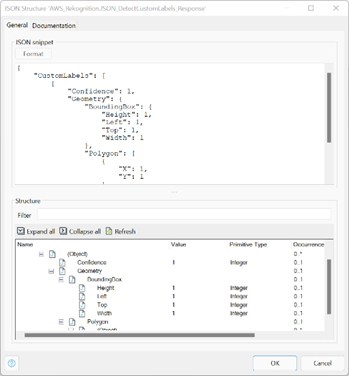
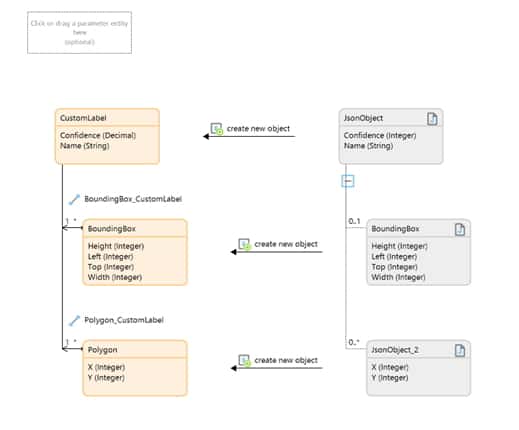
A continuación, necesitábamos una forma de enviar la imagen a AWS en un atributo de «Bytes» como una cadena codificada en Base64. Para hacer esto, creamos una definición de mensaje para Mendix System.Image, seleccionamos el atributo Contenidos y cambiamos el nombre externo a: «Bytes».
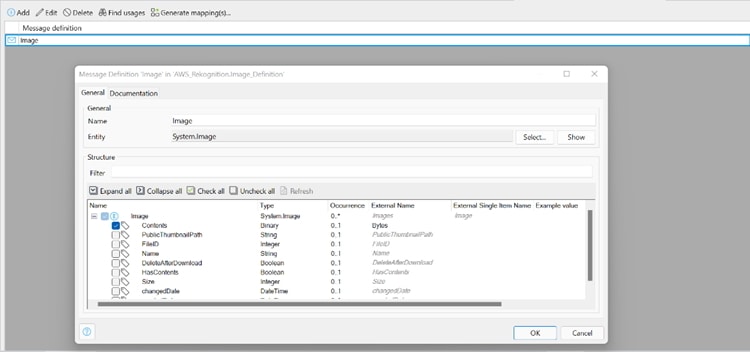
Luego usamos un mapeo de exportación y la definición de mensaje anterior, lo que nos permitió convertir la imagen al formato JSON correcto.
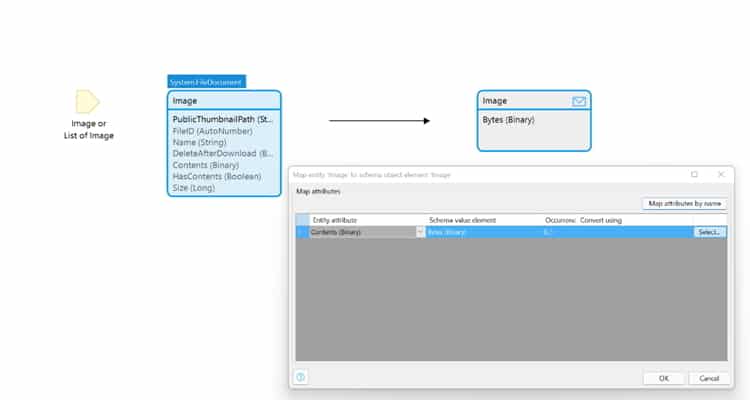
Finalmente, se requiere una llamada de Microflow para enviar la imagen al reconocimiento de AWS y devolver las etiquetas detectadas por el Modelo de aprendizaje automático. Dentro de esta llamada de microflujo tenemos una serie de parámetros requeridos por AWS Rekognition. Primero, Microflow exporta la imagen a una cadena de objetos JSON con un atributo llamado «Bytes». Esto luego se usa junto con los otros parámetros dentro de la carga útil para la acción REST.
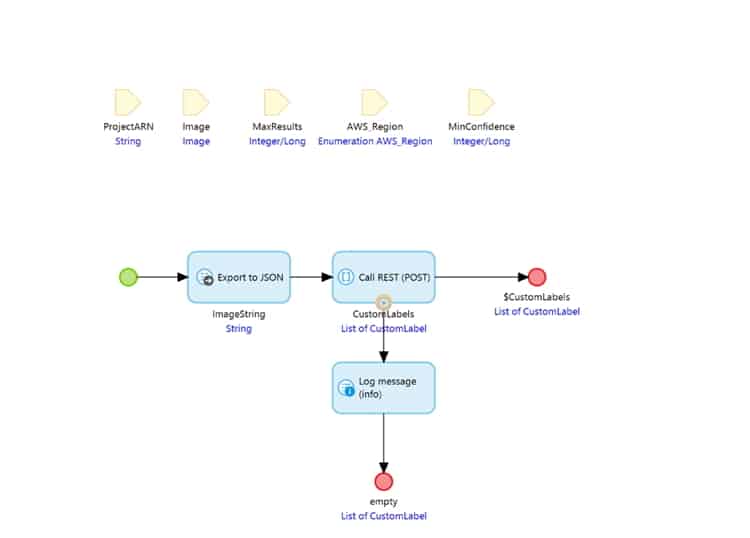
Dentro de la acción REST definimos la ubicación usando la región de AWS pasada en el parámetro. Agregue encabezados HTTP requeridos por la API. Agregue la carga útil de solicitud necesaria y la asignación de respuesta.
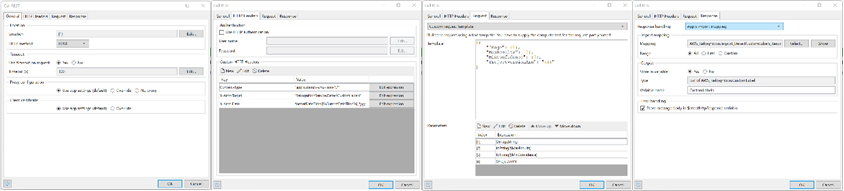
La última pieza de magia que construimos para nuestro demostrador es un poco más técnica. Las API de AWS requieren que cada llamada a la API se firme mediante un proceso llamado Sig4. Utiliza AccessKey y SecretKey para firmar la solicitud HTTP antes de enviarla para garantizar que sea auténtica. En el microflujo posterior al inicio, agregamos una acción de Java para interceptar todas las llamadas a AWS Rekognition y agregar los encabezados Sig4 adicionales requeridos antes de enviar.
Toda la integración con AWS Rekognition y Sig4 Interceptor estará disponible en Mendix Marketplace.
Escríbenos para mayor información de Mendix.
You may also like

Desarrolla aplicaciones 10 veces más rápido con Mendix
Haz que SAP ® vuele con el desarrollo Low-Code Mendix es la única plataforma de desarrollo low cod

Descubre cómo optimizar la automatización de procesos empresariales con desarrollo Low-Code
En la actualidad, las empresas manejan cientos de procesos en múltiples departamentos. Esta diversi

¿Cómo puedo usar los datos de SAP dentro de mi aplicación Mendix?
Junto con SAP, Mendix ha creado una solución de descubrimiento de API basada en archivos de metadat